
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- AWS Glue
- Opensearch
- 쿠버플로
- MLOps
- fluentd
- 데이터 아키텍처
- 데이터 플랫폼
- Kubeflow
- 쿠버네티스
- Spark
- yarn
- 하이브
- elk
- 머신러닝
- etl
- TABNET
- Python
- 파이썬
- Tabular
- 쿠버플로우
- hive
- Kubernetes
- 파이썬처럼생각하기
- MachineLearning
- Kibana
- gcp
- Minikube
- mesos
- 리눅스
- 파이썬답게생각하기
- Today
- Total
데이터를 걷는 선비
클라우드 데이터 플랫폼 계층 아키텍처 (3/3) 본문
본 포스팅은 "데이터 플랫폼 설계와 구축(다닐 즈부리브스키 외 저)"를 보고 작성했습니다.
http://acornpub.co.kr/book/cloud-data-platforms#toc
데이터 플랫폼 설계와 구축
다양한 소스에서 데이터를 수집하기 위한 패턴을 찾고, 클라우드 공급업체에서 제공하는 서비스를 활용하는 방법을 배울 수 있다.
www.acornpub.co.kr
'클라우드 데이터 플랫폼 계층 아키텍처 (2/3)'
클라우드 데이터 플랫폼 계층 아키텍처 (2/3)
본 포스팅은 "데이터 플랫폼 설계와 구축(다닐 즈부리브스키 외 저)"를 보고 작성했습니다. http://acornpub.co.kr/book/cloud-data-platforms#toc 데이터 플랫폼 설계와 구축 다양한 소스에서 데이터를 수집하
semizero.tistory.com
단순히 수집, 저장, 처리, 서비스로 구분되던 데이터 플랫폼 아키텍처에 더해 클라우드 데이터 플랫폼 아키텍처에서 특별하게 고려해야 하는 두 가지 요소가 있다.
[오케스트레이션 오버레이(Orchestration overlay)]

클라우드 데이터 플랫폼 아키텍처의 계층 구조는 메타 데이터 계층을 통해 서로 통신하는 방식을 취하기 때문에 느슨한 결합 형태이다. 그렇기에 작업이 여러 계층에 걸쳐 진행할 때 이를 조율할 컴포넌트가 필요하다.
※ 메타 데이터 계층: 데이터 파이프라인에 대한 다양한 상태 정보와 통계 정보를 관리하기 위한 저장소
<=> 오케스트레이션 계층: 여러 작업을 조정하는 목적에 맞춰진 컴포넌트
[수행 작업]
- 상호 의존성 그래프를 기반으로 여러 데이터 처리 작업을 조정할 수 있어야 한다.
- 각 작업에서 필요한 데이터 소스들, 각 작업 간 선후 관계 여부 등 데이터 처리 작업들의 의존 관계 목록화
- 작업들을 논리적으로 분리하고 의존성 그래프를 활용하면 전체 데이터 플랫폼에 주는 영향을 최소화해 각 팀들이 많은 영역의 변경 작업이 더 용이해짐
- 아파치 에어플로우(Apache Airflow), 구글 클라우드 컴포저(Cloud Composer)
- ※ 아즈카반과 우지와 같은 툴 들도 같은 용도로 사용할 수 있지만, 두 가지 툴 모두 하둡 용 작업 오케스트레이션 툴로 특별히 개발된 것이기에 유연성이 떨어진다.
- 구글은 에어플로우 기반의 관리형 서비스를 제공함으로써 오케스트레이션 계층 운영 관리 간소화
- 아마존과 MS는 오케스트레이션 기능이 포함된 ETL 툴 오버레이 제품을 제공
- 아파치 에어플로우(Apache Airflow), 구글 클라우드 컴포저(Cloud Composer)
- 작업 실패와 재시도 관리
[특성]
- 확장성(Scalability): 작업의 수가 늘어날 때 수용할 수 있어야 하고, 복잡한 의존성 그래프를 효율적으로 처리할 수 있어야 함
- 고가용성(High Availability): 장애 대응이 용이해야 함
- 유지보수성(Maintainability): 설명하기 쉽고 유지 관리가 용이한 의존성 그래프가 있어야 함
- 투명성(Transparency): 모니터링과 디버깅을 위해 작업 상태, 실행 이력, 기타 모니터링 메트릭에 대한 가시성이 제공되어야 함
[ETL 오버레이(ETL Overlay)]
ETL 툴 오버레이는 클라우드 데이터 파이프라인을 더욱 쉽게 구현하고 유지 관리하도록 하는 제품들의 모음(suite ot procudcts)이다.
일반적으로 사용자 인터페이스를 갖추고 있으며, 데이터 파이프라인을 최소한의 코딩(또는 노코드) 방식 개발이 가능하다.
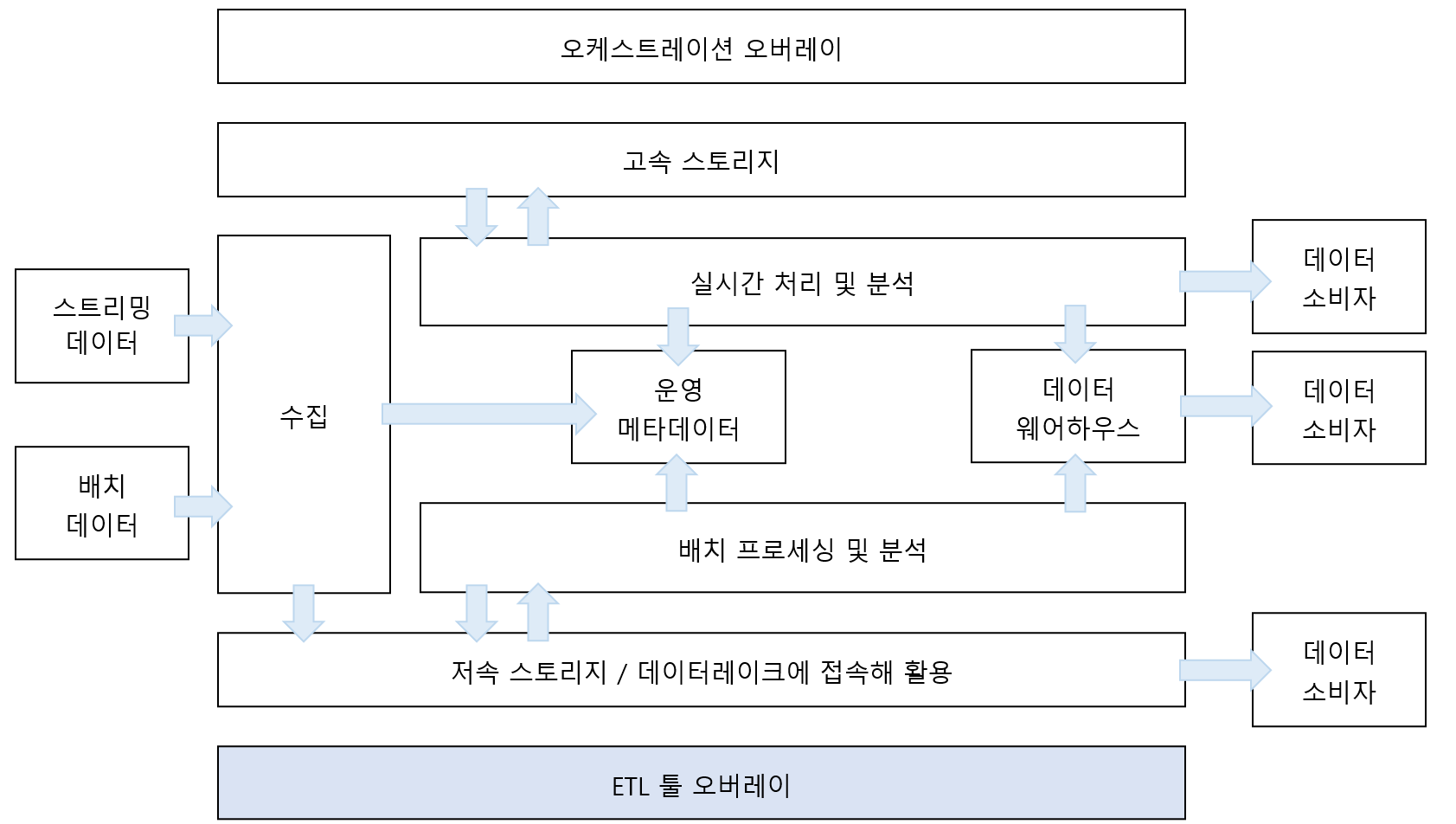
처리 계층은 비즈니스 로직 적용, 데이터 검증, 데이터 변환이 수행되는 곳이다.
주요 서비스
- 클라우드 : AWS 글루(AWS Glue), 애저 데이터 팩토리(Azure Data Factory), 구글 클라우드 데이터 퓨전(Google Cloud Data Fusion)
- 서드파티 ETL 솔루션: 탈렌드(Talend), 인포매티카(Informatica)
[수행 작업]
- 다양한 소스에서 들어오는 데이터 수집을 추가하고 구성 (수집 계층)
- 데이터 처리 파이프라인 생성 (처리 계층)
- 파이프라인에 대한 메타 데이터 저장 (메타데이터 계층)
- 다양한 작업 조율 (오케스트레이션 계층)
[특성]
- 확장성(Extensibility): 시스템에 사용자 컴포넌트를 추가할 수 있어야 한다.
- 통합(Integration): 작업 중 일부는 외부 시스템으로 위임할 수 있어야 한다.
- 자동화 성숙도(Automation maturity): ETL 솔루션 중에는 좋은 UI 기반 환경 및 노코딩을 제공하는 것들이 있음, 프로덕션 구축을 고려할 때는 툴이 지속적인 통합(CI)/ 지속적인 제공(CD) 방식에 어떻게 부합할 지 고려해야 함
- 클라우드 아키텍처 적합성(Cloud Architecture fit): 어떤 특정 솔루션을 활용했을 때 클라우드 기능을 최대한 활용할 수 있는지 신중하게 평가해야 함
[클라우드 데이터 플랫폼 계층에 활용할 수 있는 툴 매핑]
데이터 플랫폼 설계 단계에서 활용할 서비스와 툴은 PaaS, 서버리스, 오픈소스, SaaS에 이르기까지 다양한 옵션을 찾아볼 수 있다.
당연하겠지만 각 선택 옵션 간에는 트레이드 오프가 있다.
- 클라우드 네이티브 플랫폼 서비스(PaaS): AWS, GCP, Azure
- 장점: 일상적인 운영 관리 작업(서버 관리)에 할애하지 않아도 됨
- 단점: 확장성 관점에서 제약이 너무 많음
- 서버리스 솔루션(클라우드 서버리스 솔루션)
- 장점: 관리형 클라우드 환경의 모든 이점을 제공하면서도 코드를 직접 작성할 수 있어, 유연성이 높음
- 오픈소스 솔루션
- 장점: 유연성과 통제 관점에서상대적으로 이점
- 단점: 지원 작업(공수)이 비교적 많이 필요함
- 상업용 서드파트 SaaS 서비스
- 장점: 일상적인 운영 관리 작업(서버 관리)에 할애하지 않아도 됨
- 단점: 확장성 관점에서 제약이 너무 많음
현실적으로 클라우드 데이터 플랫폼을 구축할 때에는 여러 솔루션을 혼합해서 맞추는 과정을 거쳐야 한다.
그렇기에 느슨하게 결합된 계층형 아키텍처(layered architecture)가 매우 매우 중요하다!!
'BigData > Data Platform' 카테고리의 다른 글
| 느슨하게 결합된 아키텍처(Loosely Coupled Layer) (2) | 2023.01.08 |
|---|---|
| 클라우드 데이터 플랫폼 계층 아키텍처 (2/3) (0) | 2023.01.08 |
| 클라우드 데이터 플랫폼 계층 아키텍처 (1/3) (0) | 2023.01.07 |
| 클라우드 데이터 플랫폼의 빌딩 블록(building block) (0) | 2023.01.01 |



