
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- hive
- mesos
- Spark
- fluentd
- 쿠버네티스
- 하이브
- 리눅스
- Kubernetes
- 쿠버플로우
- Python
- yarn
- AWS Glue
- 쿠버플로
- 파이썬
- 데이터 아키텍처
- elk
- Tabular
- 데이터 플랫폼
- TABNET
- Minikube
- 머신러닝
- Kibana
- MLOps
- 파이썬답게생각하기
- etl
- 파이썬처럼생각하기
- MachineLearning
- Kubeflow
- gcp
- Opensearch
- Today
- Total
데이터를 걷는 선비
클라우드 데이터 플랫폼 계층 아키텍처 (1/3) 본문
본 포스팅은 "데이터 플랫폼 설계와 구축(다닐 즈부리브스키 외 저)"를 보고 작성했습니다.
http://acornpub.co.kr/book/cloud-data-platforms#toc
데이터 플랫폼 설계와 구축
다양한 소스에서 데이터를 수집하기 위한 패턴을 찾고, 클라우드 공급업체에서 제공하는 서비스를 활용하는 방법을 배울 수 있다.
www.acornpub.co.kr
https://semizero.tistory.com/7
클라우드 데이터 플랫폼의 빌딩 블록(building block)
본 포스팅은 "데이터 플랫폼 설계와 구축(다닐 즈부리브스키 외 저)"를 보고 작성했습니다. http://acornpub.co.kr/book/cloud-data-platforms#toc 데이터 플랫폼 설계와 구축 다양한 소스에서 데이터를 수집하
semizero.tistory.com
이전 게시글에서 상위 수준의 데이터 플랫폼은 계층을 알아보았다.

데이터 플랫폼의 상위 수준의 아키텍처에는 위 그림과 같이 수집(ingestion), 저장(storage), 처리(processing), 서비스(Serving) 계층의 기본 구성 요소가 있다.
다만 이러한 상위 수준의 아키텍처 그림은 복잡해진 클라우드 데이터 플랫폼을 표현하기에는 한계가 있다.
따라서 이번 포스팅에서는 아키텍처를 더욱 확대해 더욱 정교하게 구성한 데이터 플랫폼 아키텍처를 확인해보자!
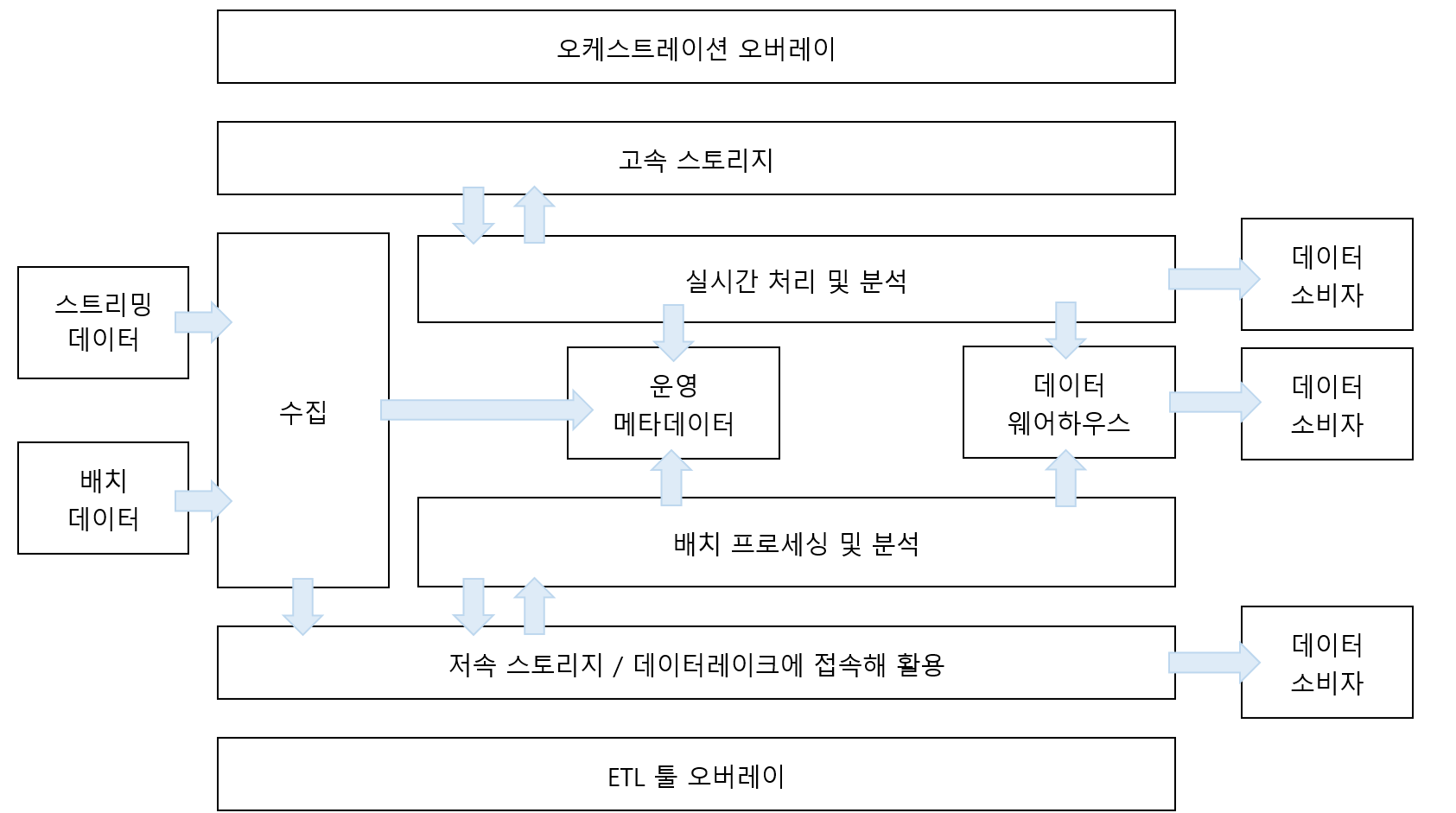
각 계층은 데이터 플랫폼 시스템에서 특정 작업을 수행하는 기능요소로,
계층의 구현을 위해 사용하고 있는 클라우드 서비스를 활용할 수도 있고, 오픈 소스, 상용 툴, 사용자가 직접 구현한 애플리 케이션으로 구성할 수도 있다.
각 계층을 간략하게 알아보기 전 해당 계층의 특징을 간단히 확인해 보면
- 수집 계층(Ingest)에서는 배치 수집과 스트리밍 수집의 차이를 보여준다.
- 저장 계층(Storage)에서는 저속 스토리지, 고속 스토리지 개념을 도입한다.
- 처리 계층(Processing)에서는 고속 스토리지, 저속 스토리지의 활용과 배치 방식 처리, 스트리밍 데이터 처리 방식을 논의한다.
- 메타 데이터 계층은 처리 계층 개선을 위해 새롭게 추가된 계층이다.
- 서비스 계층(Serving)은 데이터 웨어하우스뿐만 아니라 다른 데이터 소비자들도 포함되도록 확장됐다.
- 오버레이 계층(Overlay)은 ETL이나 오케스트레이션 작업을 위해 추가됐다.
이제 각 계층 별로 자세하게 알아보자
[수집 계층(Ingest)]
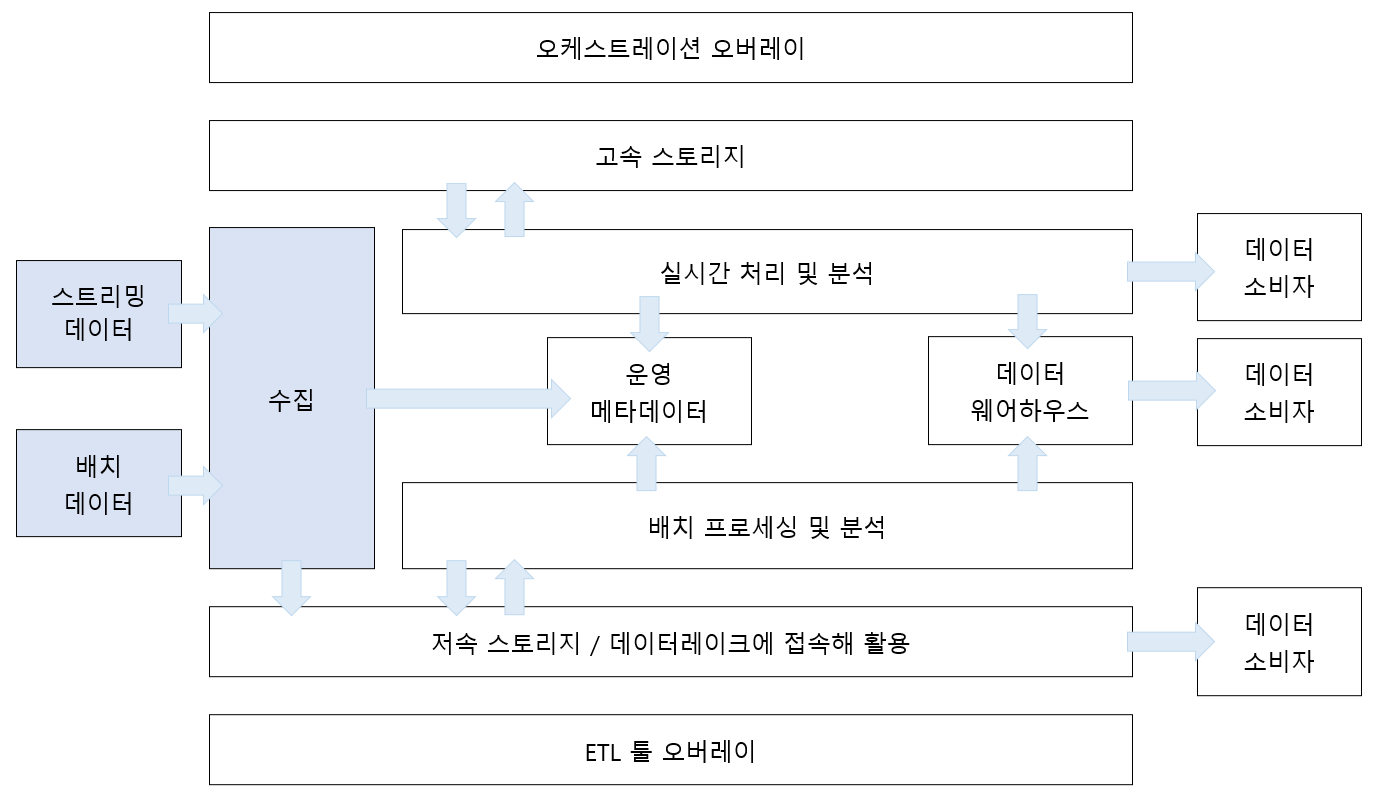
[수행 작업]
- 스트리밍 모드, 배치 모드에서 다양한 데이터 소스로 보안 연결이 가능해야 한다.
- 데이터 소스의 종류에 상관없이 데이터 수집이 가능해야 한다.
- FTP 서버(CSV, JSON, XML 파일의 수집을 위함) 등으로부터 데이터를 수집하기 위해서는 배치 데이터 파이프라인 사용
- 한 번의 하나의 이벤트 데이터에 액세스할 때에는 스트리밍 데이터 파이프라인 사용
- 배치 수집과 스트리밍 수집 둘 다 지원하도록 데이터 수집 계층을 구축하는 것이 견고한 아키텍처 사고!
- 람다 아키텍처에서는 동일한 데이터가 서로 다른 두 개의 파이프라인에서 처리되지만, 데이터 플랫폼 아키텍처에서는 배치 데이터는 배치 파이프라인에서, 스트리밍은 다른 파이프라인에서 처리
- 람다 아키텍처? 실시간 분석을 지원하는 빅데이터 아키텍처, 대량의 데이터를 실시간으로 지원하기 어려우니 배치로 만든 데이터와 실시간 데이터를 혼합해서 사용하는 방식
- 데이터 레이크에서 원시 데이터를 보존할 수 있어야 한다.
- 메타 데이터 저장소에 수집 통계와 수집 상태를 등록할 수 있어야 한다
[특성]
- 플러그형 아키텍처(Pluggable architecture): 새로운 유형의 데이터 소스가 항상 추가되기에 큰 노력 없이 새 커넥터 유형을 추가할 수 있어야 하는 구조
- 확장성(Scalability): 대량의 데이터를 처리할 수 있어야 하기에 스케일 확장이 원활해야 함
- 고가용성(High Availability): 장애 대응이 잘되어야 함
- 관측 가능성(Observability): 데이터 처리량, 지연 시간과 같은 중요 metric을 외부 모니터링 툴에 노출시켜야 한다.
[저장 계층(Storage)]
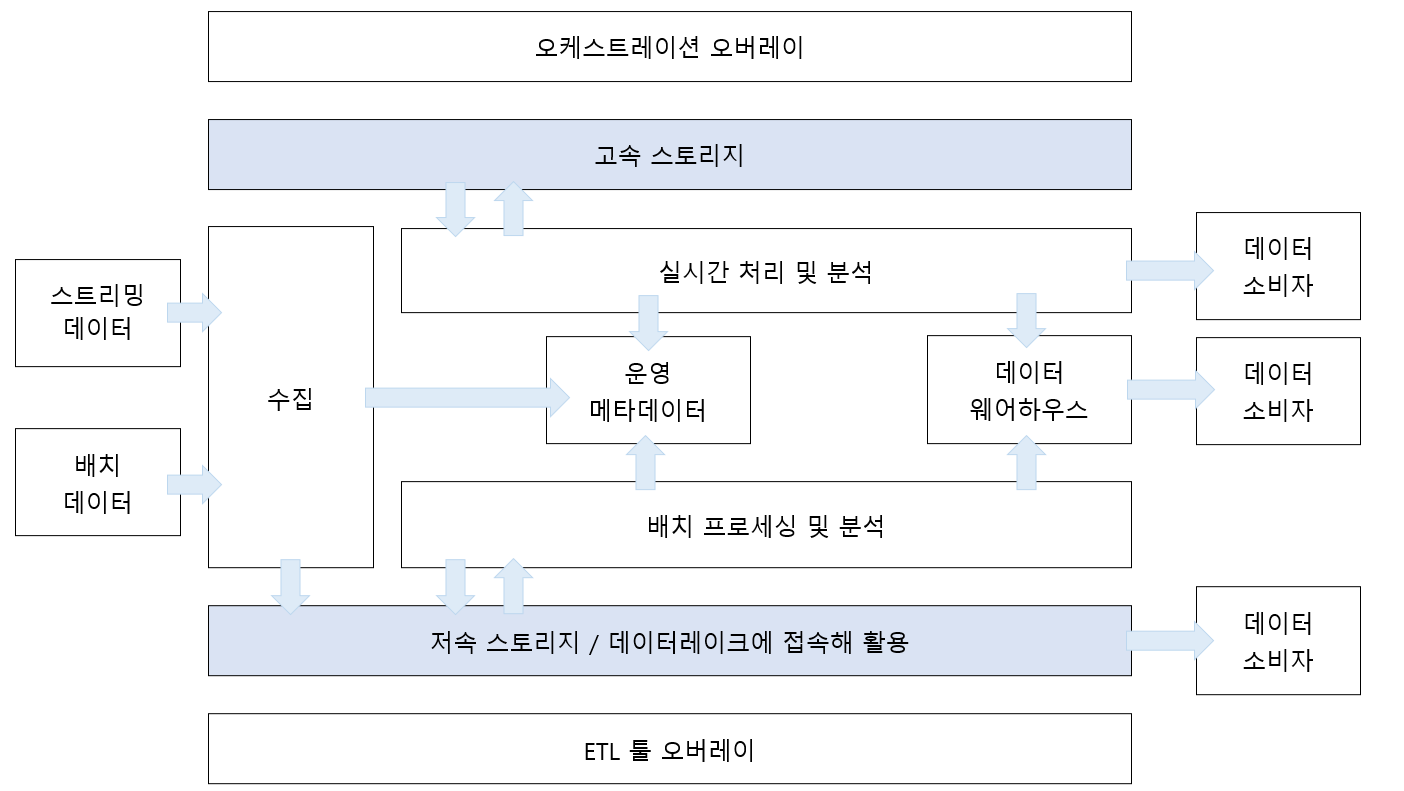
데이터 수집 계층에는 임시 캐시를 사용할 수는 있지만 일반적으로 데이터 자체를 저장하고 있지 않기 때문에, 일단 데이터가 수집 계층을 통과한 후 안정적으로 저장될 수 있어야 한다.
[저속스토리지와 고속스토리지]
※ 저속, 고속이란 특정 하드웨어 특성을 말하는 것이 아닌, 유스케이스에 따른 스토리지 소프트웨어 설계 특성을 말한다.
- 저속 스토리지
- 대용량 파일에 최적화된 클라우드 스토리지 서비스
- 모든 종류의 데이터를 비용 효율적으로 저장 가능하며, 대량의 데이터를 빠르게 읽을 수 있도록 지원
- 클라우드 공급 업체의 객체 저장소 서비스(AWS S3)
- 스토리지와 직접 컴퓨팅 서버가 없음=> 매우 비용 효율적
- But, 짧은 지연(low-latency) 액세스를 지원하지 않음: 한 번에 하나 요청할 때 응답 속도 개선에 한계!
- 고속 스토리지
- 작은 단위의 데이터를 보관하면서 매우 높은 성능 특성을 가진 클라우드 스토리지 서비스
- 단일 메시지의 읽기/쓰기 작업 시 짧은 지연(low-latency) 액세스를 지원
- 아파치 카프카 등
- But, 컴퓨팅 서버가 필요하며 비용이 훨씬 더 높다
[특성]
- 안정성(Reliable): 다양한 형태의 장애 발생상황에도 데이터를 지속적으로 유지해야 한다.
- 확장 가능성(Scalable): 최소한의 노력으로 스토리지 용량을 추가할 수 있어야 한다.
- 성능(Performant): 저속 스토리지는 대용량 데이터를 읽을 때의 읽기 성능! 고속 스토리지는 짧은 지연시간 확보!
- 비용 효율성(Cost efficient): 당연한 이야기다
'BigData > Data Platform' 카테고리의 다른 글
| 느슨하게 결합된 아키텍처(Loosely Coupled Layer) (2) | 2023.01.08 |
|---|---|
| 클라우드 데이터 플랫폼 계층 아키텍처 (3/3) (0) | 2023.01.08 |
| 클라우드 데이터 플랫폼 계층 아키텍처 (2/3) (0) | 2023.01.08 |
| 클라우드 데이터 플랫폼의 빌딩 블록(building block) (0) | 2023.01.01 |



