
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- hive
- etl
- 리눅스
- MLOps
- 데이터 아키텍처
- 머신러닝
- MachineLearning
- 파이썬답게생각하기
- Minikube
- Opensearch
- TABNET
- Python
- Kibana
- gcp
- 파이썬처럼생각하기
- yarn
- Kubeflow
- mesos
- AWS Glue
- Tabular
- Spark
- fluentd
- 하이브
- 쿠버네티스
- 데이터 플랫폼
- Kubernetes
- 쿠버플로우
- elk
- 쿠버플로
- 파이썬
- Today
- Total
데이터를 걷는 선비
[Hive] Hive 중요 개념 둘러보기(MetaStore, 파티션) 본문
[순서]
- 1. Hive metastore(메타스토어)란?
- 2. Hive 메타스토어 유형
- 3. Hive 메타스토어 설정 파라미터
- 4. Hive 버전 별 특징
- 5. Hive 테이블의 문제점
1.Hive metastore(메타스토어)란?
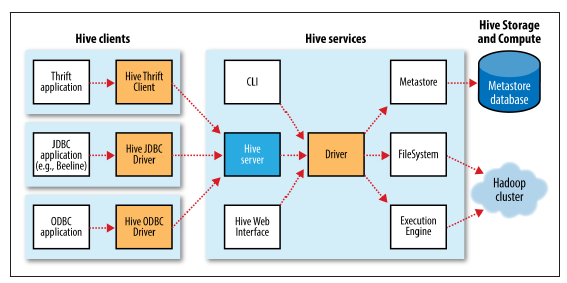
- 하이브는 테이블과 파티션과 관련된 메타정보를 모두 메타스토어에 저장합니다.
- 하이브는 기존의 RDBMS와 달리 데이터를 insert후 스키마를 입히게 되는데,
- 그때 스키마 정보를 메타스토어에서 참조하여 가져옵니다.
2.Hive 메타스토어 유형
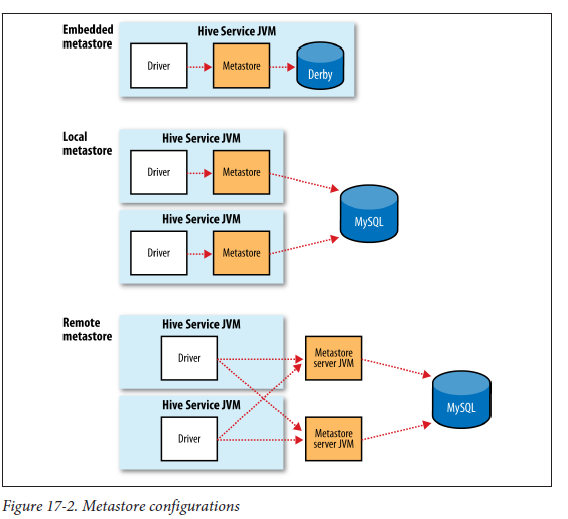
하이브의 메타스토어 유형에는 임베디드 메타스토어(Embedded metastore), 로컬 메타스토어(Local metastore), 원격 메타스토어(Remote metastore) 세가지 유형이 있습니다.
- (1) 임베디드 메타스토어(Embedded metastore)
- 하이브를 설치하면 기본적으로 임베디드 메타스토어를 사용합니다.
- 이 경우 메타스토어가 로컬 장비에 파일로 생성되므로 한번에 하나의 프로세스만 메타스토어에 접근할 수 있습니다.
- 따라서 실제 환경에서 사용해서는 안됩니다.
- 보통 DerbyDB가 임베디드 메타스토어의 default DB로 설정됩니다.
아래 포스트에서는 다른 설정 없이 기본적인 메타스토어를 활용했기 때문에 derbyDB를 메타스토어로 확인한 것을 알 수 있습니다.
https://semizero.tistory.com/66
[Hive] 하이브(v3.1.2 버전) 설치하기
[순서] 0. Pre-requisite 설치 1. 하이브 다운로드 2. 하이브 설치 3. 하이브 환경 변수 설정하기 4. hive-config.sh 파일 편집하기 5. HDFS에 Hive directory 만들기 6. hive-site.xml 파일 설정하기 7. derby database 시작
semizero.tistory.com
- (2) 로컬 메타스토어(Local metastore)
- 로컬 메타스토어의 경우 메타데이터가 모두 원격(또는 로컬)의 데이터베이스에 저장됩니다.
ex) mysql, postresql 등
- 로컬 메타스토어의 경우 메타데이터가 모두 원격(또는 로컬)의 데이터베이스에 저장됩니다.
- (3) 원격 메타스토어(Remote metastore)
- 원격 메타스토어의 경우에도 메타데이터가 모두 원격(또는 로컬)의 데이터베이스에 저장됩니다.
- 하지만 로컬 메타스토어와는 달리 메타스토어를 서비스하는 별도의 서버가 기동되며, 클라이언트는 데이터베이스에 직접 쿼리문을 날리는 대신 메타스토어 서버의 중개를 받게 됩니다.
- 이때 클라이언트와 메타스토어 서버는 thrift 통신을 사용합니다.
3.Hive 메타스토어의 설정 파라미터
하이브의 메타스토어를 설정하는 파라미터는 다음과 같습니다.
| 파라미터 | 설명 |
| javax.jdo.option.ConnectionURL | 메타데이터를 저장하는 DB의 접속 정보 |
| javax.jdo.option.ConnectionDriverName | DB에 연결할 때 사용할 JDBC 드라이버명 |
| hive.metastore.uris | 클라이언트에서 메타스토어 서버와 통신하는 URI |
| hive.metastore.local | 임베디드 또는 로컬인 경우 true, 원격인 경우 false |
| hive.metastore.warehouse.dir | 하이브 테이블이 저장되는 HDFS 상의 경로 |
Hive는 관리 혹은 내부 테이블 (managed table)과 외부 테이블 (external table) 두 가지 유형의 테이블을 나누어서 사용합니다.
4. Managed table vs External table
- 메타스토어에 저장되는 정보 중에 테이블의 종류를 지정하는 정보가 있습니다.
- Create Table시에 테이블의 종류를 지정합니다.
(메타스토어 테이블이 managed냐 external이냐라는 개념은 원본 데이터가 외부 파일에 있는지 없는지에 따라 달라지는 개념으로, 서버와 JDBC 위치에 따라 달라지는 로컬 VS 원격 메타스토어의 개념과는 사뭇 달라 보입니다.)
(1) Managed Table(Internal table)
- 생성 시 location이 hive.metastore.warehouse.dir 속성이 가르키는 directory에 저장되는 테이블
- 기본적으로 /user/hive/warehouse/databasename.db/tablename/ 위치에 저장되며,
- location 속성을 통해 테이블의 위치를 변경해 줄 수 있습니다.
- DROP table 혹은 DROP PARTITION 시, 메타스토어의 정보와 데이터가 함께 삭제되는 테이블입니다.
- 수명주기를 관리해야 하거나, 임시테이블을 생성할 때 사용
(2) External table
- 외부테이블은 외부 파일의 메타 데이터/스키마를 설명하는 테이블
- 테이블 생성 시 location을 지정 해야되는 테이블
- 파일이 이미 있거나, 원격 위치(S3,원격 HDFS)에 있을 때 사용됩니다.
- DROP table 혹은 DROP PARTITION 시, 메타스토어의 정보만 삭제되고, 데이터와 디렉토리는 남아있는 테이블입니다.
- 원본(원천) 데이터를 삭제하기 위해서는 따로 명령어를 날려야 합니다.
5. 파티션 테이블
- 파티션: 메타스토어에 저장되는 정보중의 하나로, 데이터를 디렉토리로 분리하여 저장하는 기법
- 파티션이 필요한 이유
- 성능적인 측면 => 하이브 같은 파일 기반 테이블은 기본적으로 테이블의 모든 row 정보를 읽기 때문에 데이터가 많아지면 속도가 느려집니다. 파티션 칼럼은 where 조건에서 칼럼 처럼 이용할 수 있기 때문에 처음에 읽어 들이는 데이터를 줄여서 처리 속도를 향상
- 관리적인 측면 => 파티션 단위 백업, 추가, 삭제, 변경으로 관리하기에 용이함
1) **Partitioned table**(매우 중요)
- 테이블을 하나 이상의 키로 파티셔닝(partitioning) 즉, 물리적으로 분할된 테이블
- 테이블 생성 시 partitioned by (columnname datatype) 으로 생성된 테이블
- 파티션 사용 유무를 정할 수 있지만, row가 많은 *fact table 같은 경우는 선택이 아닌 필수
- 파티션 키의 순서에 따라 HDFS 상의 directory 구조가 결정됨으로 워크로드에 따라 그 순서도 적절히 결정해야 한다
2) Non Partitioned table
- 테이블이 물리적으로 분할 되어 있지 않은 테이블
- 테이블 생성 시 partitioned by (columnname datatype)으로 파티션을 지정하지 않은 테이블
- 일반 테이블이 곧 non partitioned table
6. 정적 파티션(static partition) vs 동적 파티션(dynamic partition)
(1) 정적 파티션(static partition)
- 테이블에 데이터를 입력하는 시점에 파티션 정보를 전달
INSERT INTO TABLE tgttbl Partition (base_dt='20210713')
SELECT values
FROM srctable;- 위와 같이 정적으로 파티션을 생성할 경우 HDFS://[tbl 테이블 로케이션]/base_dt=20210713/과 같은 폴더 구조로 데이터를 생성

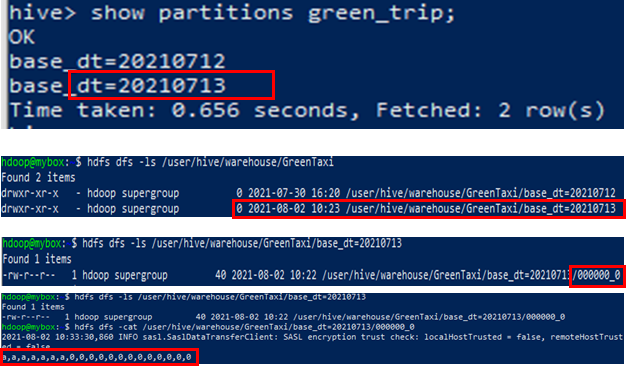
사진 수정 예정
- (2) 동적 파티션(dynamic partition)
- 칼럼의 정보를 이용하여 동적으로 파티션이 생성
INSERT INTO TABLE tgttbl Partition (base_dt)
SELECT values
,base_dt 값
FROM srctable;- 위와 같이 동적으로 파티션을 생성할 경우 base_dt의 값에 따라 파티션이 생성되고, HDFS의 폴더 구조도 그에 맞게 디렉토리 생성, 데이터를 생성
- Ex) base_dt의 값이 20210714일 경우 Hdfs://[tbl 테이블 로케이션]/base_dt=20210714/ 의 구조가 된다.
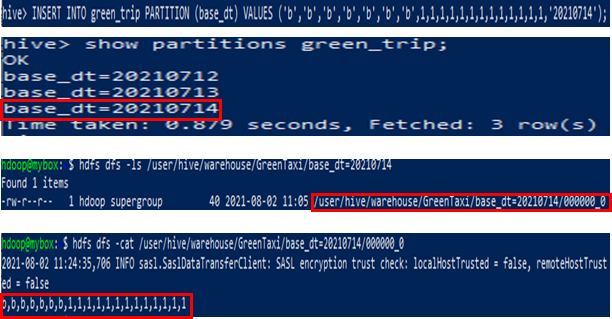
사진 수정 예정
7. Partition 조작, 일반 vs MSCK
(1) 정석적인 방법
- ADD PARTITION (추가)
ALTER TABLE tablename ADD PARTITION (base_dt=20210712) location ‘/user/hive/warehouse/GreenTaxi/base_dt=20210712’;- DROP PARTITION (제거)
ALTER TABLE tablename DROP PARTITION (base_dt=20210712);- Partitioned by (columnname datatype) (파티션 테이블생성)
Create table test1(
col1 int,
col2 string
) partitioned by (base_dt string);(2) MSCK(MetaStore ChecK)
- Hive metastore에 Hive partition이 저장되어 있지 않을 때, 말 그대로 테이블을 수리하는(Hive table의 partition을 metastore에 저장하는)작업
- HDFS의 구조에 맞게 메타 정보 전체를 업데이트(추가)
MSCK REPAIR TABLE tablename;
'BigData > Data Engineering' 카테고리의 다른 글
| [Hadoop] 하둡 (v3.3.5버전) 설치하기 (0) | 2024.02.11 |
|---|---|
| [Hive] 하이브 개념과 아키텍처 (0) | 2024.02.02 |
| [SQL] DELETE, TRUNCATE, DROP 차이 (0) | 2024.01.18 |
| [Spark] Spark Cluster Manager 종류 (0) | 2024.01.17 |
| [Spark] Spark Local mode와 Deploy Mode(local이랑 standalone 차이!!) (0) | 2024.01.17 |



