
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 데이터 아키텍처
- Opensearch
- Python
- AWS Glue
- 리눅스
- 파이썬
- Kubeflow
- 파이썬답게생각하기
- 쿠버플로우
- 데이터 플랫폼
- fluentd
- elk
- Spark
- Kibana
- hive
- mesos
- Minikube
- 하이브
- 쿠버플로
- yarn
- 머신러닝
- MachineLearning
- 쿠버네티스
- TABNET
- etl
- Kubernetes
- gcp
- Tabular
- 파이썬처럼생각하기
- MLOps
Archives
- Today
- Total
데이터를 걷는 선비
[GCP] Vertex AI 기능 살펴보기 본문
https://cloud.google.com/vertex-ai/docs/start/introduction-unified-platform?hl=ko
Vertex AI 소개 | Google Cloud
의견 보내기 Vertex AI 소개 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. Vertex AI는 ML 모델과 AI 애플리케이션을 학습 및 배포하고 AI 기반 애플리케이션에서
cloud.google.com
글로벌 퍼블릭 클라우드 社 중 GCP의 Vertex AI 툴은 구글의 Kubeflow 철학 위에 구축된 서비스이기에, 플랫폼 Kubeflow를 활용해 MLOps 관련 서비스를 구축하고자 한다면, Kubeflow 를 도입한 (것으로 추정되는) Vertex AI 의 MLOps 기능들을 벤치마킹하며 서비스를 고도화하는 방향성을 검토해봄찍하다.
※ 본 포스트에서는 구글클라우드 Vertex AI의 기능들 중 생성형 AI 기능과 주로 관련된 라벨 지정 태스크, 모델 가든, GENERATIVE AI STUDIO를 제외한 기능들을 우선 소개했다.
[Vertex AI 주요 컴포넌트]
| 분석 도구 |
대시보드 | 전체적인 MLOps 관련 기능을 한눈에 볼 수 있도록 한 도구 |
| Workbench | 분석을 진행할 수 있는 샌드박스(노트북) | |
| 파이프라인 | ML 워크플로를 GUI 기반으로 자동화, 모니터링, 제어해 프로세스 효율화 | |
| 데이터 | Feature Store | ML 특성을 구성, 저장, 제공할 수 있는 중앙 집중식 저장소 |
| 데이터 세트 관리 | ML을 학습시키는 데이터셋에 관한 정보 포함 | |
| 라벨 지정 태스크 | 데이터 항목에 대한 주석을 다는 기능 | |
| 모델 개발 |
학습 | 학습 이력에 대한 관리 기능 |
| 실험 | 다양한 모델 아키텍처, 초매개변수, 학습 환경을 추적 및 비교 분석 | |
| 메타데이터 | ML 시스템에서 사용되는 메타데이터(매개변수, 아티팩트, 측정항목) 추적 | |
| 배포 및 활용 |
모델 버전 관리 | 모델 개요를 제공하며, 새 버전을 더욱 효과적으로 구성 추적 |
| 온라인 예측 | 엔드포인트에 배포한 모델을 API를 통해 추론 | |
| 일괄 예측 | 예측요청 그룹을 통해 지정된 위치에 결과를 출력하는 배치 예측(수동/API) |

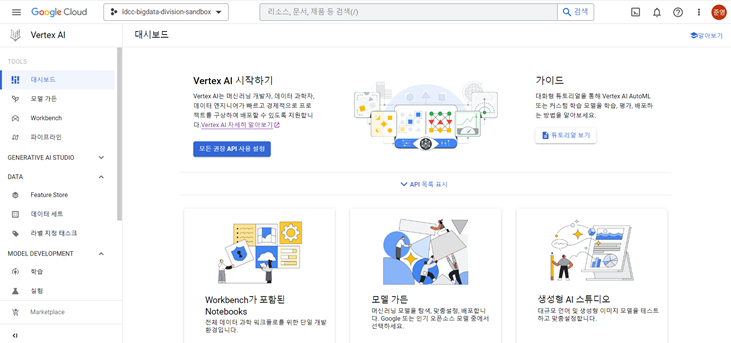
<Dashboard>
-
대시보드는 프로젝트에서 활용되는 전체적인 MLOps 관련 기능을 한 눈에 볼 수 있도록 한 도구이다.
-
학습 데이터 준비, 모델 학습, 예측 가져오기, 엔드포인트를 한 눈에 볼 수 있으며,
-
각 기능에 관한 항목들은 각 기능 전용 페이지에서도 확인 가능하다.
-
대시보드에서 관련 항목들을 클릭하면 항목 전용 페이지로 이동할 수 있다.
<Workbench>


-
분석을 진행할 수 있는 샌드박스(주피터 노트북)
-
AWS SageMaker 처럼 Vertex AI 맞춤형 SDK가 존재한다.
-
Vertex AI 파이프라인에서 노트북을 단계로 실행할 수 있다.!
-
Workbench는 관리형 노트북과 사용자 관리 노트북으로 구분되는데,
-
두 노트북 모두 주피터랩과 함께 사전 패키징되어있으며, 텐서플로, 파이토치 프레임워크 지원한다.
-
관리형 노트북 인스턴스는 주피터 노트북 기반 프로덕션 환경을 설정하고 도움이 되는 통합 기능을 미리 갖추고 있는Google 관리 컴퓨팅 인프라이며,
-
사용자 관리형 노트북 인스턴스는 네트워크, 권한 등 사용자 환경을 세부적으로 제어해야 하는 사용자에게 적합하다.
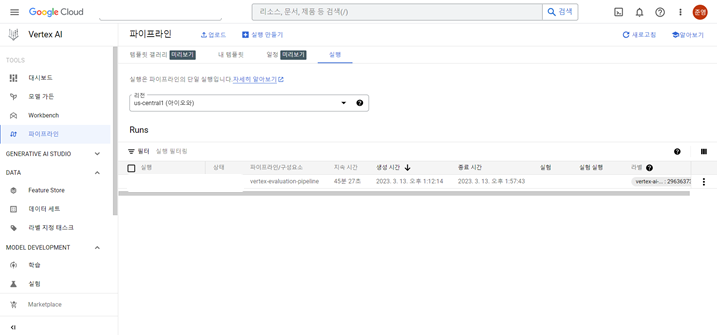
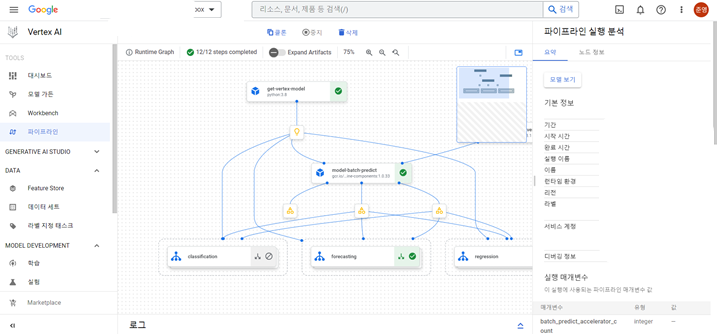
<Pipelines>
-
파이프라인은 ML 워크플로의 아티팩트를 저장해 ML 시스템을 자동화, 모니터링, 제어하는데 도움이 되는 도구로,
-
ML 워크플로의 아티팩트를 Vertex ML 메타데이터에 저장하여 워크플로 아티팩트의 계보를 분석한다.
-
여기서 아티팩트는 학습 데이터 정보, 하이퍼 파라미터 정보, 모델을 사용하는데 사용된 코드 등을 의미하는데,
-
즉 자신의 분석 모델 학습에 관한 모든 일련의 정보 및 기능을 파이프라인을 통해 모니터링 또는 제어TFX 와 Kubeflow Pipeline를 사용해 만들어진 파이프라인도 사용 가능 (텐서플로와 쿠브플로를 구글이 만들었기 때문)
<학습>

- 모델 학습 파이프라인이력을 관리하는 페이지로
- 학습 파이프라인과 연계된다.
- 하이퍼 파라미터 튜닝, 뉴럴 아키텍처 검색 등의 작업 JOB 실행 이력 관리하며,
- 모델 이름을 클릭하면 모델 레지스트리로 이동
<실험>

-
다양한 모델 아키텍처, 초매개변수, 학습 환경을 추적 및 분석하여 사용 사례에 가장 적합한 모델 파악할 수 있으며,
-
Tensorboard를 사용하면 ML 실험을 추적, 시각화, 비교하여 모델 성능을 측정할 수 있다.
<메타데이터>
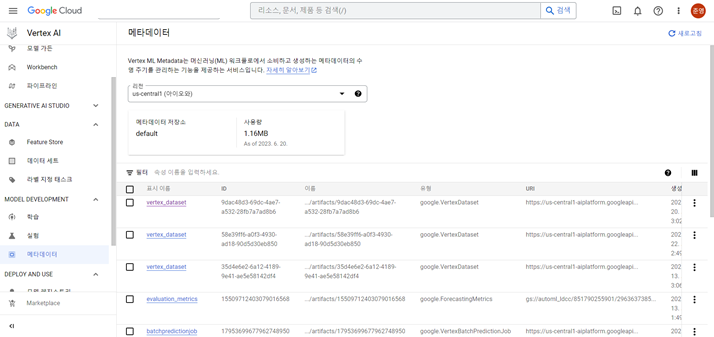

- 메타데이터는 머신러닝 워크플로에서 소비하고 생성하는 메타데이터의 수명 주기를 관리하는 기능을 제공하는 서비스
- ML 메타데이터들을 관리한다. (여기서 메타데이터는 아티팩트를 포함하는 개념!!)
- 예측 품질의 변화를 파악하기 위한 프로덕션 ML 시스템 실행 분석에 도움이 되며
- 초매개변수 집합의 효과를 비교할 수 있다.
- ML 아티펙트 계보(데이터 세트 및 모델)를 추적하면 아티팩트 생성에 기여한 요소 또는 해당 아티팩트를 사용하여 하위 아티패트를 만드는 방법 이해할 수 있다.
<모델 레지스트리>


- 모델 개요를 제공하며, 새 버전을 효과적으로 구성, 추적하고 학습할 수 있다.
- 모델 레지스트리에서 할 수 있는 것들
- 모델 평가
- 배포 및 테스트 (개별 예측에 관한 것들은 Vertex AI 온라인 예측으로 이동)
- 일괄 예측 (개별 예측에 관한 것들은 Vertex AI 일괄 예측으로 이동)
- 버전 세부정보
<온라인 예측>


- 온라인 예측은 모델 Endpoint에 수행되는 동기식 요청, 먼저 model 리소스를 Endpoint 에 배포
- 배포하면 컴퓨팅 리소스가 모델과 연결되어 지연 시간이 짧은 온라인 예측을 제공한다.
※ 온라인 예측 절차

- 클라이언트가 모델 입력값을 네트워크 전송을 위해 인코딩
- 클라이언트가 모델 서버로 인코딩된 입력값을 네트워크로 전송
- 모델 서버가 입력값 페이로드를 받아서 디코딩
- 모델 서버가 입력값(디코딩)으로 인퍼런스 결과 생산
- 모델 서버가 네트워크 전송을 위해 인퍼런스 결과 인코딩
- 모델 서버가 인코딩된 결과를 다시 클라이언트에게 네트워크를 통해 전송
<일괄 예측>


- 일괄 예측은 비동기식 요청으러
- 모델을 엔드포인트에 배포할 필요없이 model 리소스에서 직접 batchPredictionsJob을 요청한다.
- 즉각적인 응답이 필요하지 않고 단일 요청을 사용하여 누적된 데이터를 처리하고 싶은 경우에 사용되며
- 데이터는 구글 클라우드 스토리지에 저장된다.
Comments