
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Kubernetes
- hive
- 데이터 플랫폼
- mesos
- Minikube
- AWS Glue
- 쿠버플로
- 쿠버플로우
- MachineLearning
- Kubeflow
- MLOps
- 파이썬답게생각하기
- 파이썬
- 데이터 아키텍처
- Spark
- TABNET
- fluentd
- Python
- Kibana
- 하이브
- 쿠버네티스
- etl
- elk
- yarn
- 리눅스
- Opensearch
- gcp
- 머신러닝
- 파이썬처럼생각하기
- Tabular
- Today
- Total
데이터를 걷는 선비
[Kubeflow] Kubeflow의 개념과 기능들!! 본문

[Kubeflow란??]
- Kubeflow 는 구글 등에서 내부적으로 리소스 오케스트레이션 툴인 쿠버네티스 환경에서의 머신러닝을 구현하기 위해 시작한 오픈 소스 프로젝트이다.
- 쿠버네티스가 기업 플랫폼 관리 시스템으로 부상함에 따라 비슷한 방식으로 머신러닝 워크로드를 관리하는 것이 타당하다는 생태계의 분위기
-
쿠버네티스 생태계에서 사용되던 오픈 소스들을 묶어 통합적인 환경 제시
-
완전한 머신러닝 워크플로우 경험을 지원하도록 많은 애플리케이션과 프레임워크를 지원하며 다른 퍼블릭 클라우드(GCP 등)과 연계 용이
회사에서 쿠버네티스 클라우드 플랫폼 환경에서 MLOps 서비스를 구축해야 하는 업무를 맡아 자료조사를 해보았을 때,
현재 수준에서 클라우드 플랫폼 구축 방향성에 적합하며 안정적인 성능과 운영을 보장하는 것으로는 쿠버네티스 기반의 머신러닝 워크플로우 툴인 Kubeflow가 있다는 것을 알았다.
일반적으로 MLOps 툴로는 MLflow가 유명했고 Kubeflow는 쿠버네티스라는 장벽이 있기에,
가급적 MLflow와 BentoML과 같은 서빙툴을 활용하려 했으나, 아래와 같은 Kubeflow의 장점들 때문에 결국 Kubeflow를 통해 MLOps 플랫폼을 구축해야 겠다는 생각을 했다.
[MLOps 관련 오픈소스 기능 비교표]
| 구분 | Kubeflow | MLflow |
| 더 빠르고 일관적인 배포 | O (KServe라는 전문 배포 오픈소스 Adds-On 가능) |
△ (기능이 제한적이라 BentoML같은 서빙 툴과 연계) |
| 안전한 보안을 위해 포트나 컴포넌트 접근에 대한 더 나은 통제 |
O (Istio를 통한 아이덴티티 기반 인증과 승인) |
X (개인 로컬에 적합) |
| 리소스 공급 과잉에 대한 보호로 비용 절감 |
O (Istio를 통한 할당량과 접근 제어 지원) |
X (개인 로컬에 적합) |
| 워크플로 오케스트레이션과 메타데이터 수집 |
O (쿠버네티스 기반) |
O (추적 기능 존재) |
| 중앙화된 모니터링과 로깅 | O (파이프라인 툴 기능이 핵심) |
O (추적 기능 존재) |
| 모델을 안전하고 확장이 가능하도록 프로덕션으로 옮기는 인프라스트럭쳐 |
O (쿠버네티스 기반) |
X (파이썬 프로그램) |
단순하게 보았을 때 Kubeflow와 MLflow는 MLOps 오픈소스라는 점은 같았지만,
쿠버네티스 환경을 기반으로 두고 있다는 점과 파이썬 프로그램이라는 태생적인 한계에서 오는 기본적인 차이가 크다는 것을 확인할 수 있었다.
즉, 회사에서 자신들만의 머신러닝 서비스를 하고자 한다면 MLflow를 다른 서빙 툴과 연계해서 사용해도 상관이 없지만, 클라우드 플랫폼 상에서 MLOps 서비스를 MLflow로 만들기에는 무리가 있었다.
[Kubeflow로 ML실험 단계와 생산 단계 구현]

Kubeflow는 모델 실험 학습을 위한 사실상 모든 알고리즘 패키지를 지원한다.
- 모델 실험 학습
- Jupyter notebook : web 기반 파이선 인터프리터로, 데이터 분석에 많이 사용하는 tool
- 페어링: Kubeflow에서 ML 모델을 쉽게 학습하고 배포할 수 있는 Python 패키지
- 파이프라인: Kubeflow의 pipeline은 ML workflow의 모든 구성 요소(컴포넌트)를 의미
- 최적의 성능을 내기 위한 하이퍼 파라미터 튜닝
- Katib :ML 모델의 Hyper parameter 및 아키텍쳐를 자동으로 튜닝하는 kubeflow의 컴포넌트

또한, Kubeflow는 모델 Production을 위한 과정을 지원하는데, 쿠버네티스 환경 기반이기에 모델 배포와 관리를 원할히 할 수 있다는 장점이 있다.
- 실제 데이터를 가지고 모델 학습
- Chainer / MPI MXNet / PyTorch / TFJob 등: Trainig Job을 통한 학습
- 서버에 모델 배포
- KFServing(KServe) / TFServing / Seldon 등: 학습된 모델을 실제 배포할 때 사용하는 컴포넌트
- 모델 성능 모니터링
- Metadata: 모델, 모델 실행, 데이터 셋 등 기타 Artifact에 대한 정보를 의미하는 컴포넌트
- Tensorboard: Tensorflow가 포함하는 graph visualization tool
[Kubeflow 주요 컴포넌트]
Kubeflow를 설치한 뒤,
로그인을 하면 아래와 같은 대시보드를 통해 Kubeflow의 기능(컴포넌트)들을 한 눈에 확인할 수 있다.
상세 기능 활용법에 대해서는 다음 포스트에서 설명하고, 이번 포스트에서는 컴포넌트들에 어떤 것들이 있는지 알아보자.
<Dashboard>

- Kubeflow에서 일어나는 사용자 활동을 위한 중앙 허브
- 컴포넌트들의 통합 포탈
- 사용자별로 화면이 나누어 질 수 있다.
<Notebooks>

- 쿠버네티스위에서 주피터 노트북을 사용할 수 있는 주피터 허브 서비스
- 모델 개발을 위한 첫번째 컴포넌트이며 다른 컴포넌트들과 연동 가능
- 인증과 접근 통제 관점에서 쿠브플로 인프라스트럭처의 나머지 부분과 잘 통합된다.
- 사용자 간 주피터 노트북 공유도 가능하다
<Pipelines>


- Kubeflow Pipeline은 핵심 컨포넌트!!
- ML 워크플로를 구성할 파이프라인 툴을 서비스
- ML 파이프라인의 오케스트레이션을 쿠버네티스 인프라 스트럭처의 컨테이너로 단순화한 것이 특징!
- 파이썬 코드를 kfp 또는 dsl 라이브러리를 활용해 Kubeflow pipeline과 호환되도록 작성하면 활용할 수 있다
- 각 컴포넌트 실행으로부터의 메타데이터(MySQL)와 아티팩트(S3,Minio 등) 를 모두 생산하고 저장된다.
- 각각의 Pipeline 들은 Experiments(KFP) 페이지에서 관리되며, 실행은 관련해서는 Runs 페이지에서 관리할 수 있다.
<Katib>

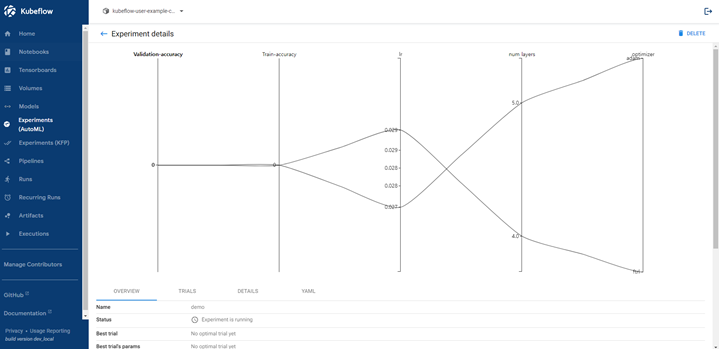
- Katib은 크게 (1) 하이퍼파라미터 최적화(Hyper Parameter Optimization, HPO)와 (2) 뉴럴 아키텍처 탐색(Neural Architecture Search)로 나누어져 있다
- (1) 하이퍼 파라미터 최적화는 학습률, 드롭아웃 비율, 뉴럴 넷의 레이어 수, 비용 함수 등을 최적화하며
- (2) 뉴럴 아키텍처 탐색은 최적의 뉴럴 네트워크를 디자인 하는 것을 목표로 한다.
- 그리드 서치, 랜덤 서치, 베이지안 최적화, 하이퍼밴드 등의 검색 알고리즘 방법론으로 최적의 하이퍼파라미터를 탐색
- 메트릭 컬렉터라는 사이드카 컨테이너를 통해 메트릭 수집
'Machine Learning > MLOps' 카테고리의 다른 글
| [Kubeflow] 쿠브플로 아키텍처(Kubeflow Architecture) 개요 (0) | 2023.08.14 |
|---|---|
| [CI/CD] Jenkins(젠킨스) 개념 및 실습(Python) (0) | 2023.08.10 |
| [CI/CD] Jenkins(젠킨스) 개념 및 설치 방법!! (1) | 2023.07.29 |
| [Kubeflow] Minikube로 Kubeflow(v1.7) 설치하기 (0) | 2023.07.23 |
| [MLOps] ML Workflow(머신러닝 워크플로) 란? (0) | 2023.07.03 |



