
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 데이터 아키텍처
- etl
- Kibana
- TABNET
- 파이썬답게생각하기
- mesos
- 파이썬처럼생각하기
- Opensearch
- elk
- Kubeflow
- Kubernetes
- 데이터 플랫폼
- 리눅스
- 쿠버플로
- 하이브
- MachineLearning
- MLOps
- gcp
- Spark
- AWS Glue
- 파이썬
- Minikube
- 쿠버네티스
- yarn
- 머신러닝
- fluentd
- Tabular
- Python
- 쿠버플로우
- hive
Archives
- Today
- Total
데이터를 걷는 선비
[Glue] AWS Glue Cralwer(크롤러)로 테이블 만들기 실습 본문
이전 포스팅에서 Glue에 대한 개념을 알아보았지만 막상 개념이 너무 두루뭉술하다.
이번 포스팅에서는 직접 Glue Cralwer로 데이터 카탈로그 데이터 베이스에 테이블을 생성하는 실습을 통해 Glue를 자세히 알아보자
https://semizero.tistory.com/5
[Glue] AWS Glue 개념 정리
AWS 관련 업무를 하거나, 관련 자격증(Machine Learning Specialty, Data Analytics) 에 대해서 공부하다 보면 자주 등장하는 AWS Glue의 개념에 대해서 간단히 알아보겠습니다. https://aws.amazon.com/ko/glue/ 서버리스
semizero.tistory.com
[실습]
- 미션 : S3(데이터 스토어) 에 적재된 데이터를 Glue 크롤러를 활용해 크롤링하고 생성된 데이터 카탈로그를 Glue 데이터 베이스의 테이블에 적재!!
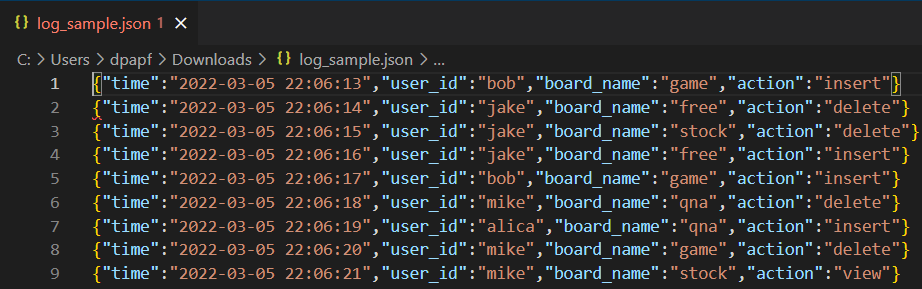
- 실습 데이터 : log_sample.json
log_sample.json
0.09MB
- 개념
- AWS Glue 데이터 카탈로그에는 Glue 환경을 관리하는데 도움이 되는 테이블 정의, 작업 정의, 스키마 및 기타 제어 정보가 담겨 있음
- AWS Glue 데이터 크롤러는 소스 또는 대상 데이터에 연결하고, 우선순위가 지정된 분류기 목록을 거치면서 데이터의 스키마를 결정한 후, AWS Glue 데이터 카탈로그에 메타데이터 생성

[목록 확인하기]
- Cralwer를 통해 S3 데이터 소스를 Crawling 한 스키마는 Database 아래에 Table에 저장된다.
- Cralwer를 활용하기 위해서는 데이터 소스의 대상이 되는 S3에 데이터가 적재되어 있어야 하며, output의 위치가 되는 Databse가 존재해야 한다!!

[database 생성]
- output 위치가 될 데이터 베이스를 만들어준다.

[S3 데이터 적재]
- 데이터 소스(S3)에 데이터를 적재해준다.
- 참고로 Glue 크롤러는 S3 뿐만 아니라 RDS, S3, RedShift, Aurora, DynamoDB 등 다양한 스토어를 데이터 소스로 사용할 수 있다.
- [주의] S3 에 데이터를 업로드할 때 꼭 퍼블릭 활성화를 통해 데이터 읽기가 가능하도록 해야 한다!!

[크롤러 생성 시작]
- 크롤러 생성 버튼을 누른 후 이름 입력


[데이터 소스 추가]
- [Add a data source] 버튼을 통해 데이터 소스 입력
- [주의] 소스가 될 데이터가 아니라, 폴더 경로를 입력해 주어야 한다=> 크롤러가 폴더 내에 데이터 모두를 크롤링한다 생각하면 된다.



[IAM 역할 설정]
- Glue를 위한 IAM 역할 설정
- 복잡한 설정 필요 없이 [Create new IAM role]을 누르고 이름만 설정해주면 간편히 role을 설정할 수 있다.


[Output 설정 및 스케줄링 설정]
- 데이터 베이스를 선택해준다.
- [추가 옵션]을 통해 온디맨드로 운영할 지, 일정한 스케줄에서 운영할 지 결정할 수 있다.

[크롤러 설정 완료 및 크롤러 RUN]
- 큰 무리 없이 크롤러 설정이 완료된 것을 확인할 수 있다.

- [Run] 버튼을 누르면 크롤러가 실행된다.
- [주의] 실습용 데이터는 규모가 작기 때문에 많은 비용이 들지 않지만, 규모가 클 경우 많은 비용이 들기에 주의해야 한다.


[Table에 스키마 생성 확인]
- 데이터 베이스의 테이블 아래 스키마가 잘 형성된 것을 볼 수 있다


'Cloud > AWS' 카테고리의 다른 글
| [Data Platform] AWS 데이터 플랫폼 아키텍처 (0) | 2023.01.09 |
|---|---|
| [Glue] AWS Glue 개념 정리 (0) | 2022.12.27 |
'Cloud/AWS' Related Articles
more


Comments